
Erik Norman is an engineer at heart with deep hands-on experience in large-scale cloud environments, M&A-driven modernisation, and FinOps consulting for large enterprises, including major European commercial airlines. He has spent years designing and implementing architectures that dramatically cut cloud costs while improving performance and reliability. His playbook, data-driven solution architecture, goes far beyond dashboards and waste-hunting.
Most FinOps programmes focus on what happens after an architecture exists. Rightsizing instances, buying commitments, chasing idle resources. Erik Norman argues this is working downstream of the real problem. The biggest savings, and the biggest gains in speed, reliability, and quality, come from somewhere most FinOps practitioners never look: the moment the architecture is being designed. His central thesis is simple and, for many organisations, uncomfortable: data dictates architecture. Build around actual access patterns, and cost efficiency becomes a byproduct of correctness. Skip that step, and you'll be optimising the same misshapen system for the rest of its life.
Data Dictates Architecture: The Principle Most Organisations Skip
Erik's core argument is that most architecture decisions are made without the information that should drive them. Product teams aren't asked to specify data access patterns. Sometimes because nobody thinks to ask, sometimes because it's perceived as too technical, often because time pressure kills the conversation before it starts. The result is predictable: you ask for a cloud webshop and you get something built to generic best practices, not to your actual data needs.
Q: Please describe the concept of Data-Driven Architecture and why it is important.
Data-driven architecture is an approach to designing systems where decisions about how to build and organize the system are based on the types of data it will handle. This includes understanding what kind of information is collected, how often it is accessed, understanding expected usage and volume, or any rules or retention regulations that apply to it. By focusing on these data patterns, architects can choose the framework and structures to efficiently manage and process the data, leading to more effective and cost-efficient systems.
Q: How does that differ from other architectural approaches and why is it better?
Most organisations have a gap here. Product teams aren't typically positioned to specify data access patterns. You'll find multiple reasons: nobody asked them for it, it's perceived as too technical, it's unclear what to specify, and then there's time pressure. Without these specifications, someone else fills the gaps: a team asks for a cloud webshop and they receive an application built to generic best practices, not to their actual needs. Data-driven architecture closes that gap by making these specifications mandatory.
The benefits of this data-driven approach are cascading. The system becomes optimized for the specific data needs, leading to better performance and, incidentally, cost efficiency. It forces communication between product managers and engineers, ensuring that the system's architecture aligns closely with business goals and regulatory requirements. This approach can prevent inefficiencies and significantly reduce costs by tailoring the architecture to the actual data usage patterns.
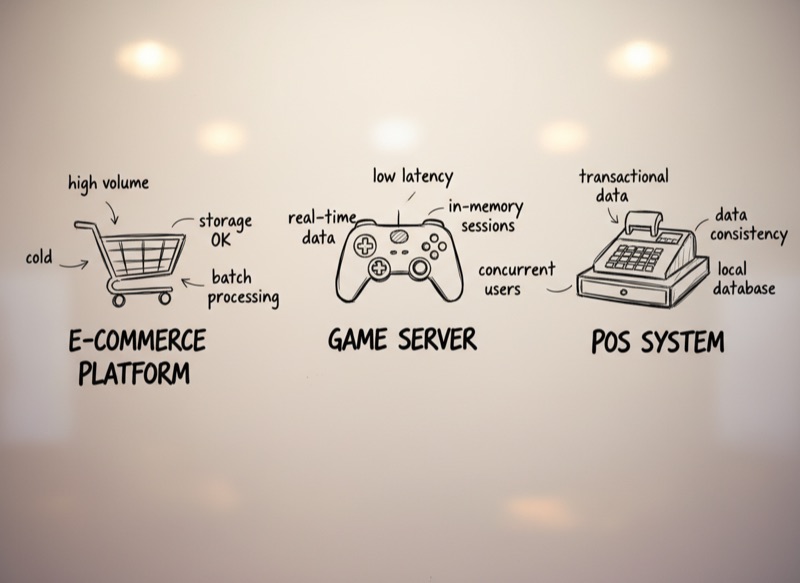
Consider three scenarios: transactional data, such as sales and payments. If you need it for audit purposes and compliance only, the data will be rarely accessed and can be stored in cold storage. If you want analytics and reporting, something completely different is needed. E-commerce platforms like Amazon require databases designed for massive scale and consistency guarantees; a small neighbourhood delicatessen shop's POS system has such low transaction volume that the database choice becomes almost irrelevant. A server for a massive online game cannot handle sessions in memory, and compression would degrade performance; a small-scale Intranet application can be implemented as thin clients and a server with in-memory session data and stateful compression.
See the pattern? The data dictates architecture. Build your blocks around specific data access patterns, and architecture becomes optimized for both performance and cost.
Carrots and Sticks: How to Make Data-Driven Architecture Stick
Introducing data-driven architecture to an organisation is not a tooling problem. It's an organisational one. Erik's recipe involves non-technical data specification templates that product managers can actually fill out, a curated library of building blocks maintained by a dedicated team, gamification to create a carrot, and chargeback multipliers to apply a stick. The result is a flip from push to pull: teams request FinOps help when they need it, rather than FinOps spamming out recommendations that get ignored.

Q: How do you introduce such a shift in architectural methodology and how do you make it stick in the organization?
Product managers already focus on what matters: users and the data they consume and generate. Think about it: data is simply information. This definition predates IT. If we provide data specification templates that remain non-technical, we can encourage product managers to embrace data specifications as a crucial step in the entire 'from idea to product' process.
Appoint a technical product management team (or interest group) to curate a central library of building blocks and organize workshops whenever a new data access pattern emerges or new technology is available. This team bridges product and architecture, ensuring blocks remain relevant and teams learn from patterns as they evolve.
If you build applications using only these building blocks, you achieve a theoretical optimum: best performance and efficiency. Gamify the efficiency score to create a carrot, and introduce chargeback multipliers to apply a stick. Budget pressure naturally motivates teams to proactively seek optimization strategies. This inverts the FinOps flow: instead of the FinOps team spamming out recommendations, teams request help when they need it, allowing FinOps to focus on high-value conversations.
Case Study: The POS SaaS Platform That Cut Usage 98.4% by Asking the Right Question
The strongest proof of any architecture methodology is a concrete example, and Erik has one. A point-of-sale SaaS platform serving large retail operators was doing everything "right" by traditional FinOps standards. Rightsized, well-architected review passed, tenant databases tuned. The problem wasn't in the implementation. It was in the data access pattern nobody had questioned.

Q: Can you give us a concrete example of a data-driven re-architecture and realised savings as a result?
One of the most powerful examples of data-driven re-architecture I encountered was a point-of-sale (POS) SaaS platform for large retail operators. The platform served multiple large retail tenants, each with many stores, and each store had several desktop POS systems. The cloud backend's job was to keep local POS apps and web shops updated with product prices, promotions, and catalog changes, with the business requirement being "near real-time" propagation of changes.
A POS SaaS platform served large retail operators with many stores, many tenants, and multiple desktops per store. Desktop POS clients polled the cloud backend every second to check for updates, generating approximately 2.6 million seconds per month × four desktops per store × many stores, resulting in tens of millions of requests per month. The backend had dedicated databases per tenant, was heavily scaled out, and had already passed well-architected reviews. From a traditional FinOps standpoint, they had already "done everything right."
Stepping back from the implementation revealed the actual access pattern: most of the time, nothing changes. When changes happen, they're often bulk updates: new campaigns or price changes across many items. POS clients don't need per-second license or data checks if nothing has changed. The entire polling pattern was architecturally wrong for the data it was serving.
Event-driven notifications replaced constant polling. A message queue was introduced for connected stores. When changes occurred, if the delta fit in the notification, the message itself was the update. Clients applied the delta directly, eliminating the need for constant checks. License checks were minimised and decoupled from the hot path. Request volume dropped from millions per month to a handful per store. Tenant databases and app servers could be consolidated, and the backend infrastructure was massively downsized. The architectural change was minimal, but it led to a cost reduction of 98.4%.
This wasn't achieved by hunting for idle resources or switching pricing models. It came from rethinking the data access pattern and aligning the architecture to it. No amount of rightsizing could have delivered this result, because rightsizing operates on the assumption that the architecture is correct. Sometimes it isn't.
Why Each Organisation Needs Its Own Building Blocks
One of the most common questions Erik gets is whether a universal library of building blocks could serve as a cross-industry standard. His answer is firm: no. The blocks are too subject to internal and external constraints, too shaped by engineering confidence levels and regulatory context, and most importantly, too dependent on organisational ownership. Teams that help build the library are the ones that trust and use it. Teams that inherit it from elsewhere treat it as bureaucratic overhead.

Q: Erik, do you believe it's possible to create a universal library of building blocks that could serve as a cross-industry standard, or should each organization develop its own tailored library?
The answer is no; each organization should develop its own library of building blocks. Building blocks are highly subject to architectural opinion and must align with the specific internal and external constraints of an organization. Factors such as the confidence level of engineers, organizational goals, regulatory requirements, and unique business processes all influence the design and implementation of these blocks.
While a universal standard might seem appealing, it would likely lack the flexibility and specificity needed to address the diverse needs and challenges faced by different organizations. Therefore, it's more effective for each organization to build and evolve its own library, ensuring that it meets its particular requirements and fosters buy-in from its teams.
Furthermore, when teams are involved in the creation and evolution of their building blocks, they are more likely to trust and adopt these solutions. This involvement ensures that the blocks are not only technically sound but also practically applicable to the organization's unique context. By participating in the development process, team members gain a deeper understanding of the rationale behind architectural decisions, which enhances their commitment to using the blocks effectively.
This collaborative approach also encourages continuous improvement, as teams feel empowered to suggest refinements and innovations that align with evolving business needs.
Key Takeaways
Erik's playbook reframes FinOps as an architecture discipline where cost efficiency is a byproduct of data-pattern alignment:
Data Dictates Architecture. Build around actual data access patterns, and cost efficiency becomes a natural outcome. Skip that step and you'll be optimising a misshapen system for the rest of its life.
The Product-Engineering Gap. Most organisations never ask product managers to specify data access patterns. Closing that gap, with non-technical templates, is the first move.
98.4% Came From Questioning the Pattern. The POS case proves it: no amount of rightsizing could have matched the result. The savings came from rethinking the architecture, not optimising the implementation.
Carrots and Sticks Together. Gamify the efficiency score. Apply chargeback multipliers. Budget pressure naturally motivates teams to seek optimisation rather than resist it.
Invert the FinOps Flow. Teams should request help when they need it, not dodge recommendations pushed at them. That inversion is the sign the practice is working.
Build Your Own Library. Universal block libraries fail because they lack organisational ownership. Teams trust what they help build. Start small, evolve through workshops, keep it local.
Implementation Roadmap
Appoint
Create a technical product management team (or interest group) responsible for curating the building block library and running pattern workshops.
Template
Build non-technical data specification templates that product managers can fill out as part of the idea-to-product process. Keep them free of engineering jargon.
Seed
Build the initial library of blocks around the data access patterns you already understand. Storage tiering, compute execution models, compression strategies. Capture them as reusable primitives.
Mandate
Make data specifications a required input for every feature request. Without the specification, the request doesn't proceed. Enforce consistently from the top.
Incentivise
Implement a cost index and chargeback multipliers that reward teams using the library efficiently and apply gentle pressure on teams that avoid it. Gamify where possible.
Evolve
Run workshops whenever a new data access pattern emerges or new technology becomes available. The library should grow and adapt, not calcify.
The Bottom Line
Data-driven architecture isn't just about cost savings. It's about building better systems. When you design around actual data patterns, you get faster performance, higher reliability, more maintainable code, and dramatically lower costs. The savings don't come from cutting corners; they come from eliminating unnecessary complexity that never should have existed in the first place.
For senior leadership, Erik's argument recasts FinOps in a much more strategic frame than most organisations give it. If your FinOps practice begins and ends with rightsizing and commitment management, you are optimising around a fixed architecture. The organisations that will outperform over the next decade are the ones that recognise the architecture itself is the lever.
About Erik Norman
Erik Norman is an engineer and cloud architect with deep experience in large-scale cloud environments, M&A-driven modernisation, and FinOps consulting for large enterprises including major European commercial airlines. He specialises in data-driven solution architecture that aligns cost efficiency with performance and reliability. Connect with Erik on LinkedIn.
The perspectives expressed reflect the interviewee's personal experience and views. Cloud Value Lab publishes practitioner-led thought leadership at the intersection of FinOps, GreenOps, and AI Economics.